
CS345, Machine Learning
Prof. Alvarez
Text Recognition
Handwritten text recognition is an interesting and challenging domain
to which machine learning techniques can been applied. Recognizing
free-form text is quite difficult; good performance requires the
consideration of syntactical information as well as visual data.
For visual data only, character recognition (classification
of individual character images) is a good test case.
NIST Handwritten Digits Database
NIST has compiled a database of handwritten numerals (0-9).
Some sample images that I extracted from the NIST database
appear below.
The image files are originally in a binary format; extracting them
from the database is not difficult but requires care regarding details
of machine representation such as big endian vs. little endian formats.
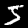
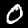
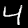
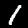
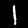
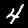
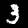
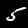
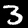
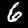
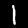
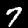
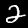
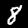
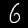

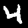
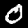
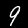
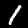
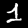
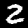
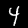
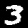
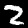
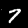
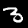
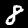
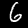
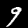
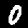
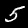
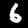
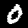
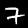
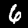
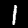
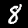
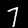
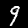
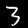
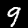
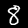

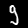
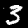
Notice that
although the NIST images are scaled and centered in the image frame,
there are significant variations among the different images
for a given class (digit).
For example, the digit '7' appears in both crossed and uncrossed variants,
and the vertical slant varies quit a bit among instances of the digit '1'.
Such variations make automated recognition a non-trivial task.
The results of extensive experimentation with the NIST dataset
obtained via a variety of machine learning techniques appears
in the following paper. We will discuss some of these techniques
in this course.
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner.
"Gradient-based learning applied to document recognition."
Proceedings of the IEEE,
86(11):2278-2324, November 1998.
A subset of the NIST dataset containing 60,000 instances,
downloads of the above paper, and error rates for several
classifiers are all available at:
http://yann.lecun.com/exdb/mnist/.